September 26th, 2021
Oracle Analytics Cloud (OAC): 5 Best Practices For Data Modeling
Data-driven decision-making is inevitable in today’s business world.
Companies of all sizes are investing heavily in data visualization tools and analytics platforms such as Oracle Analytics Cloud or OAC.
Oracle Analytics Cloud (OAC): Jumpstart Guide >>
Though data visualizations play a critical role in uncovering insights, they rely heavily on data models to get the job done.
In this blog post, we’ll cover 5 data modeling tips for OAC users.
What is Data Modeling?
In simple terms, data modeling is the process of creating multiple data tables (ex: Customers, Orders, Products, etc) and creating appropriate associations between them.
Before you start modeling the data for analysis in any data viz/analytics platform (including OAC), you should understand the importance of data literacy.
How to Improve OBIEE Data Literacy With a Fail-safe Approach? >>
In order to create the right data models, one has to understand the 2 types of data tables – Fact tables, and Dimension tables.
Fact Tables
Fact tables are tables recording the transactional data.
For example, the Orders table is a fact table. A customer can place more than one order for various products at different times.
In the Orders table, the Order ID column has unique values for each record and used to identify each order.
Dimension Tables
Dimension tables are the tables in which the data stored are less likely to change with time.
For example, the Customers table, which stores the customer info such as first and last names, email addresses, phone numbers, cities, state, country, etc.
The information about a customer is less likely to change. Even if it changes, the data is updated in the existing record, rather than creating a new record for that customer.
How to Retain OBIEE/OAC Joins and Aggregations in Power BI? >>
In the case of dimension tables, the users will have to be aware of the column used as the primary key. (i.e) the column with a unique id (say customer id, product id) assigned for each record in a dimension table.
These keys will be used to associate the dimension tables data with the fact tables data for analysis.
Once you’re sure about which fact and dimension tables, and the primary keys you’re going to use for analysis, you can go ahead with your data modeling.
What is Oracle Analytics Cloud?
Oracle Analytics Cloud is Oracle’s cloud-based Analytics platform. The platform is suitable for individuals, teams, and enterprises.
OAC comes with a tonne of features ranging from data preparation to data visualization to machine learning to Natural Language (NLP/NLG) and mobile capabilities.
One of the major advantages of OAC is it doesn’t limit the scope of self-service to data preparation and data visualization. It extends the scope to the Machine Learning features as well, helping users build no-code models.
Another benefit of OAC (especially over Oracle Analytics Server – OAS) is that organizations don’t have to worry about hosting or updates. They are all taken care of by Oracle. OAC comes with automated lifecycle management capabilities.
OAC vs OAS – When to Choose What? >>
If you’re using Oracle Business Intelligence Enterprise Edition (OBIEE), the migration path to OAC migration depends mainly on the OBIEE version (11g or 12c) you use. However, in both cases, the steps are simple as exporting files to OAC and getting started with it, as both are Oracle products.
Many organizations, despite moving to OAC, are connecting Power BI or Tableau to OAC (and OBIEE/OAS) via BI Connector, as a major chunk of their users are already familiarized with Power BI or Tableau, and prefer sticking to them.
Supercharge OBIEE and OAC With Power BI/Tableau >>
From a pricing point of view, OAC is priced based on the number of users/month or OCPU/hour.
OAC comes in multiple plans within the professional and enterprise editions, allowing organizations to flexibly choose the best option that suits their needs. More pricing and plan info here.
Now that we’ve looked at the basic information about data modeling and OAC, let’s jump into the core topic – 5 best practices for data modeling in OAC.
OAC: 5 Best Practices for Data Modelling
In OAC, the 5 best practices for data modeling are:
- Use star schema
- Create separate logical table for each fact/dimension tables
- Rename logical column names with presentation-friendly labels
- Retain only the required columns in the logical layer
- Follow a standard naming convention
Let’s now look at each of them in detail.
Snowflake For Data Lake Analytics – Jumpstart Guide >>
- Use star schema
In OAC, the data model used for analysis must be a star schema. When you identify the fact and dimension tables, you must associate them in the star schema model.
Star schema might sound to be a technical term, but it’s a lot simpler.
To explain star schema with an example, let’s consider 3 tables:
- Orders (Fact table)
- Customers (Dimension table) and
- Products (Dimension table)
5 DOs and DON’Ts of Cloud Data Warehousing >>
The Customer ID is the primary key in the customers table, and used for associating with the Orders table. Similarly, the Product ID is used to associate the products data with the Orders table.
Now the relationship between the 3 tables – Customers, Products, and Orders will look like below:
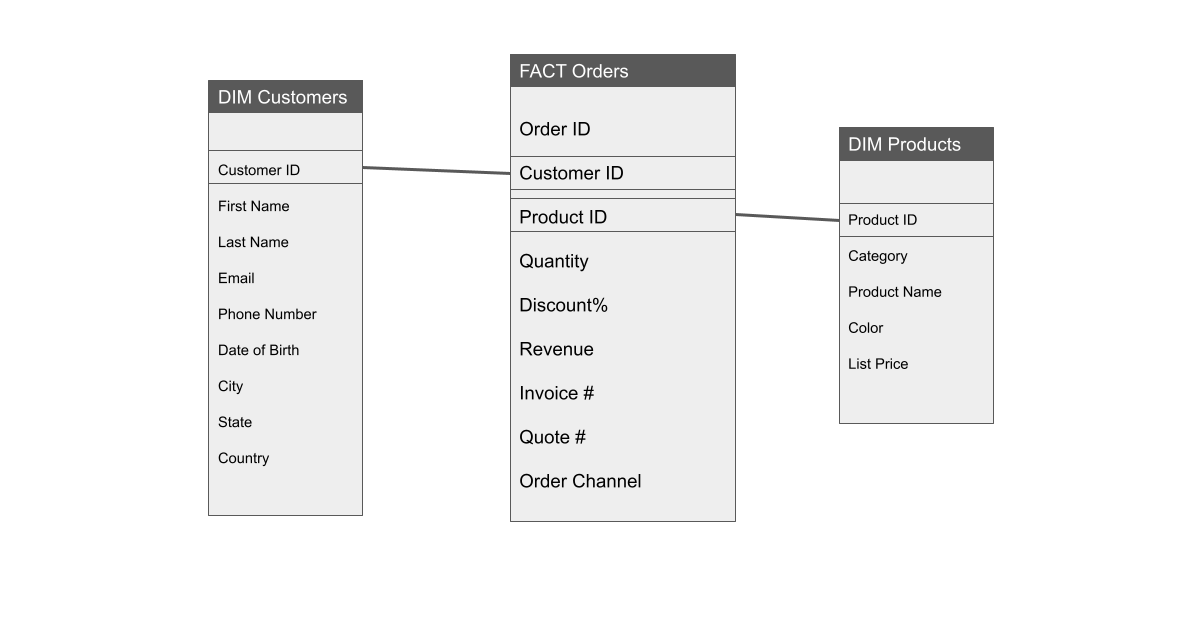
Now you have created a data model with a single fact table, associated with multiple dimension tables successfully.
This model is called a star schema, as there aren’t any relationships within the dimension tables and all of them are connected through a single fact table.
Your data in the physical layer could contain different types of schemas, but your data model in OAC’s logical layer must always be modeled with star schemas.
In other words, avoid data associations between dimension tables in the logical layer, and associate them all to the fact table.
Even in the physical layer, it is highly recommended to use star schemas in order to improve performance.
Always create a separate logical table for each fact and dimension tables used in your analysis.
Never combine or merge more than one dimension tables with each other. The same is applicable for the fact tables as well.
[Ultimate Guide] Moderinize OBIEE, Oracle Analytics With Power BI [eBook] >>
It is also good to apply the necessary filters especially to your dimension tables, and narrow down to the data you need for analysis.
Having separate logical tables will help identify the tables faster, and avoid errors.
It is a best practice to rename the columns in your logical tables with presentation-friendly labels.
This step will help avoid the overhead task of labeling the data in your reports and dashboards.
Furthermore, it also makes it easy to trace the underlying columns of a report when the column name and presentation label are the same.
That’s a great time-saver from a report creator’s view.
Also, retain only the columns you need (or) remove the columns you don’t need for analysis in each of the logical tables, be it a fact or dimension table.
The physical layer might be flooded with a large number of data points in each table. In most cases, they are probably created for better tracking (from a development standpoint) or for compliance.
These data points might not make much sense to your analysis. So what you can do is just retain the columns you need in the logical layer, and remove the unwanted columns.
This best practice is applicable for both fact and dimension tables.
But don’t forget to retain the primary keys in the logical layer. You may not use the column with the primary key directly for your analysis, but they help you create associations between your fact and dimension tables, and cannot be ignored!
When creating tables, it is always good to follow a standard naming convention. For example, many companies prefix a Dim before the dimension table names and Fact before the fact table names.
You can also follow additional naming conventions for 2 critical reasons.
9 Best Practices for Connecting Tableau to OBIEE/OAC >>
The first reason is for your own understanding when you look at the tables after a significant period of time. We tend to forget stuff when we create tables in an ad-hoc way for a quick analysis.
If you want to reuse the tables for your analysis in the future, or for scheduling reports, naming the tables in an ad-hoc way doesn’t work.
The second reason is to help your team members using the same assets (be it reports or datasets or projects or dashboards) as yourself to stay on the same page, and analyze the data without disturbing the commonly used assets.
So when you’re creating a naming convention, don’t forget to have a chat with your team to help them all stay on the same page. It is also good to prepare a document on the naming conventions and share it with other users.
[Bonus Tip] Reuse the data models from datasets in multiple projects
On top of the best practices for data modeling, we’d like to share one bonus tip as well.
Create the data models in the datasets, instead of creating the model in the Projects.
This will help you save time and use the modeled datasets across multiple projects, instead of recreating the same data model for each project.